색인(Index)란?
찾아보기, 즉 색인을 만들어 놓으면 어떤 키워드를 가진 사이트나 파일이 어디에 있는지 검색을 통해 알 수 있다.
색인은 key + 해당 key를 key로 하는 레코드의 페이지 번호로 구성되어 있다.
색인의 목적은 개체의 레코드를 검색하기 위해
ex) 사람의 레코드는 주민등록번호, 이름, 집주소, 전화번호 ....
이 중 주민등록번호는 키(key)에 해당한다.
키는 각 레코드를 대표할 수 있는 필드이며 하나 또는 다수의 필드로 이루어 질 수 있다.
즉 주민등록번호는 하나만으로 그 사람이 누구인지 대표할 수 있지만 이름이나 집주소로는 그사람을 대표할 수 없다.
하지만 이름과 전화번호를 조합하면 그사람을 대표하는 키가 될 수 있다.
레코드에 포함된 각 항목을 필드라고 한다.
내장색인: 색인이 메모리 내에 있는 경우
외장색인: 색인이 메모리 밖에 있는 경우
색인을 위한 자료구조
- 이진 검색 트리(오늘 정리할거) - 자식 노드가 최대 2개
- 균형 이진 검색 트리 - 트리의 높이를 자동으로 조정하여 균형을 유지한는 트리
- 다진 검색 트리 - 자식 노드가 3개 이상
- 해시 테이블
배열도 색인으로 쓸 수는 있지만 매우 비효율적이고 비실용적이다.
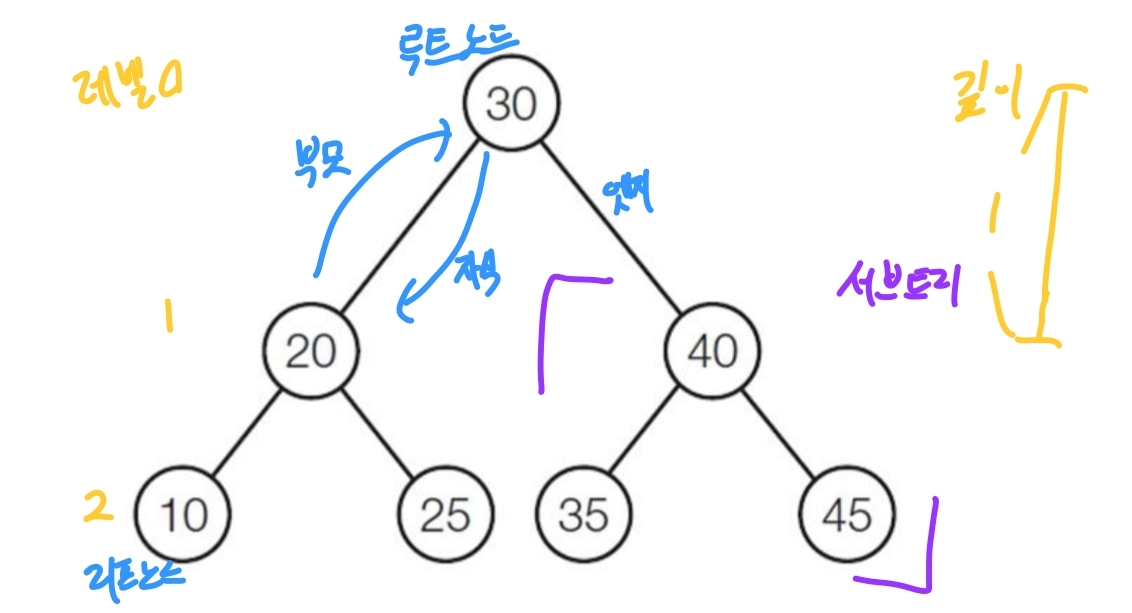
트리의 주요 개념
- 루트(root) : 트리에 최상단에 있는 노드, 부모가 없는 노드
- 노드(node) : 트리의 각 요소로, 데이터를 포함하고 자식 노드에 대한 링크를 가질 수 있다.
- 엣지(edge) : 노드와 노드를 연결하는 선, 부모와 자식 노드간의 관계를 나타낸다.
- 자식 노드(child) : 특정 노드로부터 직접 연결된 하위 노드
- 부모 노드(Parent) : 특정 노드를 가리키는 상위 노드
- 잎 노드(leaf) : 자식이 없는 노드, 말단 노드
- 서브 트리(subtree) : 트리의 부분 트리로, 특정 노드를 루트로 가지는 하위 트리
- 레벨(level) : 트리에서 특정 노드의 깊이를 나타냄, 루트 노드는 레벨 0
- 깊이(depth) : 트리에서 루트 노드부터 특정 노드까지의 거리
- 검색 트리 : 모든 노드가 검색을 위한 key값을 가진 트리
이진 검색 트리의 조건
- 노드는 모두 서로 다른 키를 갖음(중복 x)
- 각 노드는 최대 2개의 자식을 갖음
- 임의의 노드의 키는
- 자신의 좌 서브트리에 있는 모든 노드의 키보다 크고
- 자신의 우 서브트리에 있는 모든 노드의 키보다 작다
- 다시 말해 max(좌 서브트리 노드의 키값) < 부모 노드 키 값 < min(우 서브트리 노드의 키값)
따라서 이진 검색 트리에 대한 접근은 루트 노드부터 시작한다.
루트 노드에 값에 따라 나머지 노드들이 왼쪽 서브트리에 위치할지 오른쪽 서브트리에 위치할지 결정되기 때문이다.
이진 검색 트리의 표현
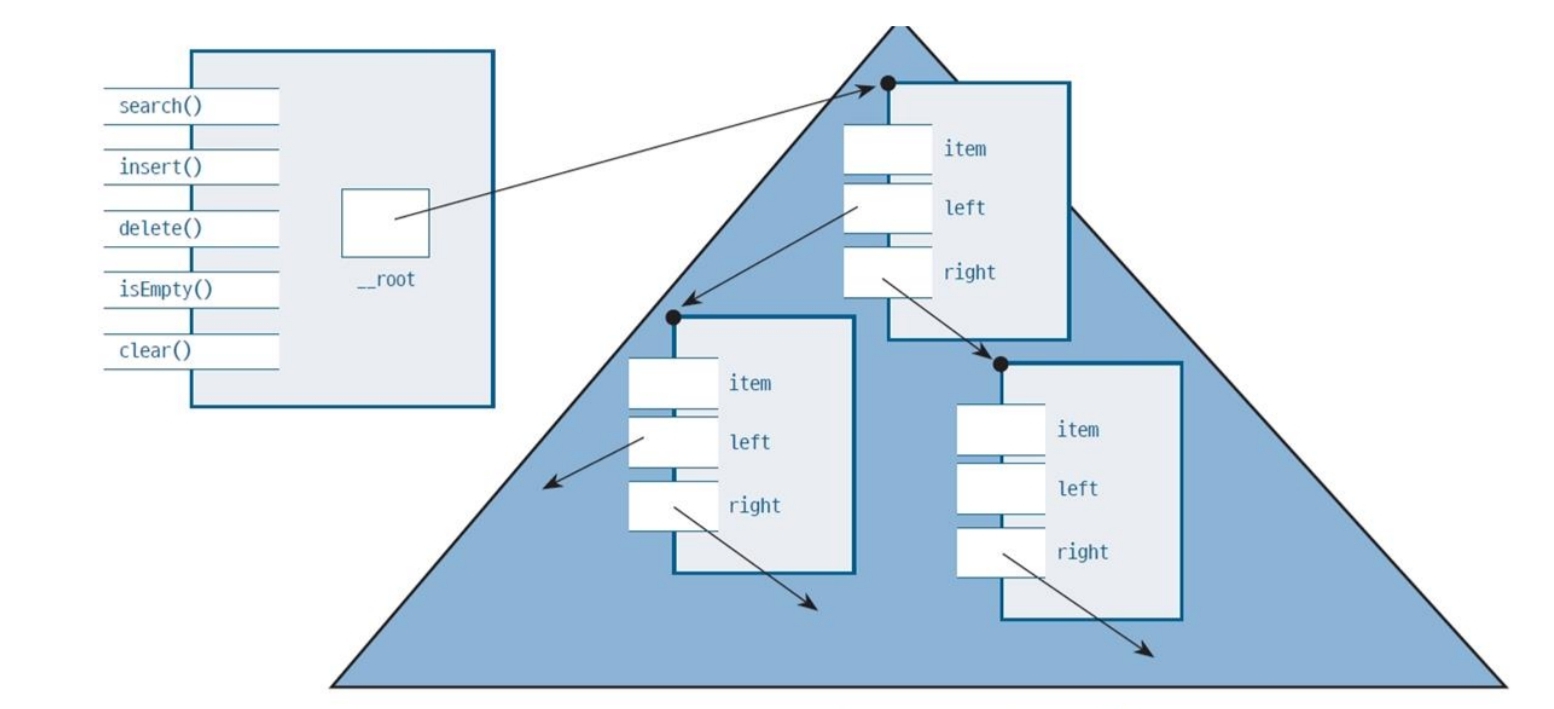
이진 검색 트리는 BinarySearchTree 객체 하나와 TreeNode 객체들로 만들어졌다.
이진 검색 트리의 다른 노드들은 루트에서 링크로 연결됨
이진 검색 트리 알고리즘 구현
1. 검색
- 기본원리
t: 트리의 루트 노드
x: 검색하고자 하는 키
루트 노드에서 시작해서 가능한 경우의 수
1. 루트 노드의 키 값이 찾으려는 값인 경우 -> 루트 노드 반환
2. 찾으려는 키 값이 루트노드보다 작은 경우 -> 좌 서브트리의 루트 노드에서 동일한 과정 반복
3. 찾으려는 키 값이 루트노드보다 큰 경우 -> 우 서브트리의 루트 노드에서 동일한 과정 반복
def search(self,x): # 이진 검색트리에서 x값 찾기
return __searchItem(self.__root, x) # 루트 노드와 x값을 인자로 입력
def __searchItem(self, tNode ,x):
if (tNode == None): # 탐색 중 리프 노드에 도달한 경우(찾는 값 없음)
return None
elif (x==tNode.item): # 찾고 있는 x값과 현재노드의 키 값이 같은경우
return tNode # tNode의 키 값 반환
elif (x < tNode.item): # 찾고 있는 x값이 현재 노드의 키 값보다 작은 경우
return self.__searchItem(tNode.left, x) # 현재노드의 좌 서브트리의 루트노드로 동일한 과정 반복
else: # 찾고 있는 x값이 현재 노드의 키 값보다 큰 경우
return self.__searchItem(tNode.right, x) # 현재노드의 우 서브트리의 루트노드로 동일한 과정 반복
2. 삽입
- 기본원리
노드가 삽입될 자리를 찾아 null 링크를 새 노드의 링크로 바꾸는 작업
검색과 동일하게 노드와 삽입할 값(x)을 비교하며 루트노드부터 서브트리로 내려가다가 null이 나오는 위치에 x를 키로 하는 노드를 t의 부모 밑에 매달아 값을 삽입한다.
def insert(self, newItem): # 이진 검색 트리에 newItem 삽입하기
self.__root = self.__insertItem(self.__root, newItem)
def __insertItem(self, tNode, newItem):
if (tNode == None): # 현재 노드가 존재하지 않는 경우(현재 노드의 부모노드가 리프노드)
tNode = TreeNode(newItem, None, None) # 현재 노드에 새로운 키 값(newItem)을 가지는 리프노드 만들기
elif (newItem < tNode.item): # 삽입할 값이 현재 노드의 키 값보다 작은 경우
tNode.left = self.__insertItem(tNode.left, newItem) # 현재 노드의 좌 서브트리에서 과정 반복
else: # 삽입할 값이 현재 노드의 키 값보다 큰 경우
tNode.right = self.__insertItem(tNode.right, newItem) # 현재 노드의 우 서브트리에서 과정 반복
return tNode
3. 삭제
- 기본원리
삭제는 삽입과 다르게 삭제할 노드가 정해진 이후 추가로 해야 할 일이 남아있다.
삭제할 노드(r)가 정해지면 발생하는 3가지 경우
- r이 리프 노드인 경우 -> 그냥 r 을 삭제
- r의 자식 노드가 1개인 경우 -> r의 부모노드와 r의 자식노드를 직접연결
- r의 자식 노드가 2개인 경우 -> r의 오른쪽 서브트리의 최소 원소 노드(s)를 찾고 s를 r자리로 복사하고 r을 삭제한다
왜? 오른쪽 서브트리의 최소원소를 복사해오는가?
우 서브트리에는 삭제할 노드보다 큰 값만 존재한다.
따라서 우 서브트리의 최솟값이 삭제할 노드의 위치에 오게 되면
좌 서브트리의 모든 노드의 값보다 크고 우 서브트리의 모든 노드의 값보다 작아 이진 검색 트리의 조건을 만족한다.
def delete(self, x):
self.__root = self.__deleteItem(self.__root, x) # 루트 노드부터 삭제작업 시작
def __deleteItem(self, tNode, x):
if (tNode == None): # 삭제하려는 값이 없는 경우
return None
elif (x == tNode.item): # 현재 노드의 키값이 삭제하려는 값인 경우
tNode = self.__deleteNode(tNode) # 현재노드를 삭제하고 트리를 갱신
elif (x < tNode.item): # 삭제하려는 값이 현재 노드의 키 값 보다 작은 경우
tNode.left = self.__deleteItem(tNode.left, x) # 좌 서브트리로 가서 같은 작업 반복
else: # 삭제하려는 값이 현재 노드의 키 값 보다 큰 경우
tNode.right = self.__deleteItem(tNode.right, x) # 우 서브트리로 가서 같은 작업 반복
return tNode # 삭제 후 갱신된 현재 서브트리의 루트를 반환하여 부모 노드와 연결
def __deleteNode(self, tNode):
if tNode.left == None and tNode.right == None: # tNode가 리프노드인 경우
return None
elif tNode.left == None: # tNode의 자식이 오른쪽에만 있는경우
return tNode.right
elif tNode.right == None: # tNode의 자식이 왼쪽에만 있는 경우
return tNode.left
else: # tNode의 두 자식이 둘 다 있는 경우
(rtnItem, rtnNode) = self.deleteMinItem(tNode.right) # 우서브트리의 최솟값 노드를 받아옴
tNode.item = rtnItem
tNode.right = rtnNode
return tNode
def __deleteMinItem(self, tNode): # 우 서브트리에서 최솟값 찾기
if tNode.left == None: # 해당 노드의 키 값보다 작은 값들은 항상 왼쪽에 존재하기에 왼 자식이 없다면 해당 노드가 최솟값이다.
return (tNode.item, tNode.right) # 해당 노드 반환
else:
(rtnItem, rtnNode) = self.__deleteMinItem(tNode.left) # 해당 노드의 왼쪽 자식이 존재한다면 왼쪽 자식으로 이동 해서 같은 작업 반복
tNode.left = rtnNode # 왼쪽 자식이 없을때 까지
return (rtnNode, tNode)
삭제 알고리즘이 굉장히 복잡한데 트리를 갱신하는 과정은 항상 재귀적으로 처리된다는 것을 명심해야한다.
노드가 삭제된다는 의미는 트리의 연결관계를 갱신하는 것이다.
10
/
5
\
7 이런 트리에서 노드 5를 삭제한다는 의미는 10과 7을 바로 이어준다는 의미이다.
10
/
7 삽입이나 검색과 달리 삭제는 삭제되는 노드의 자식 노드들 까지 연결을 고려해야 한다.
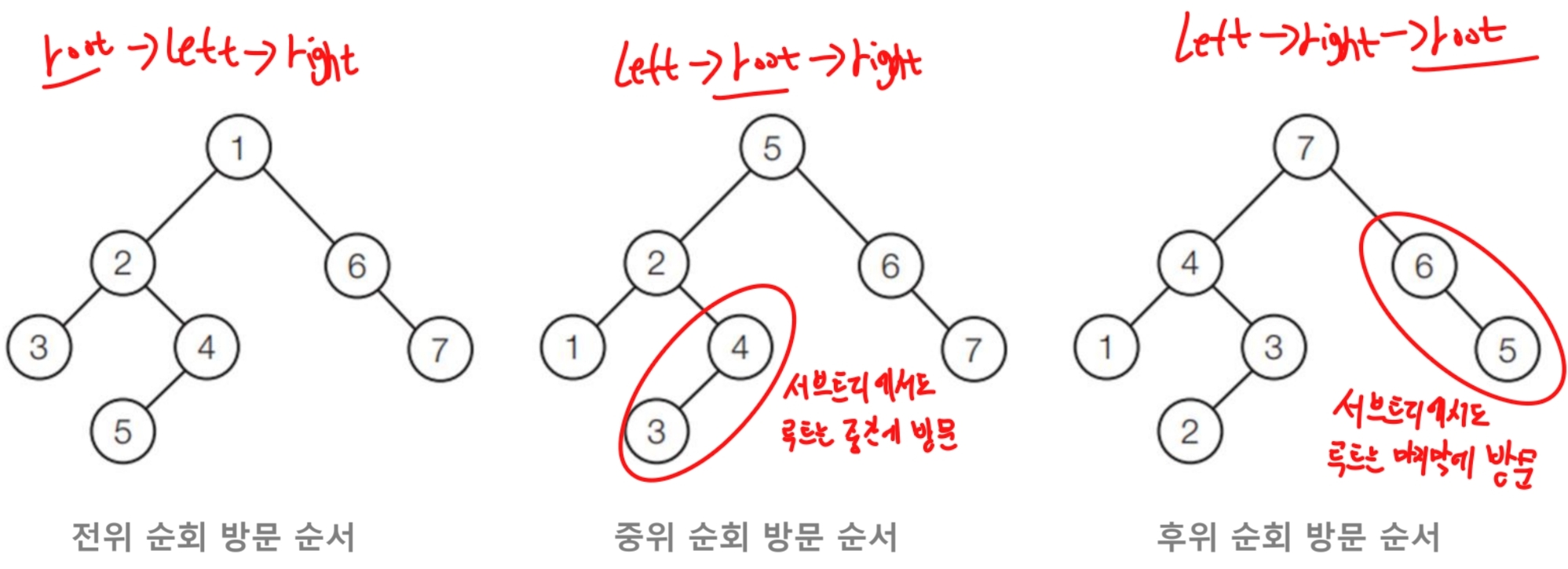
순회(Traversal)
이진 트리에서 순회란?
모든 노드를 방문하는것
- 전위 순회 : 루트를 제일 먼저 방문하기(Root > Left > Right)
- 중위 순회 : 루트를 중간에 방문하기(Left > Root > Right)
- 후위 순회 : 루트를 맨 뒤에 방문하기 (Left > Right > Root)
이진 검색 트리 작업의 효율

'[자료 구조 및 알고리즘]' 카테고리의 다른 글
| [자료구조 및 알고리즘] 그래프 (2) | 2024.12.07 |
|---|---|
| [자료구조 및 알고리즘] 해시 테이블 (0) | 2024.12.04 |
| [자료구조 및 알고리즘] 균형 검색 트리 - AVL 트리 (0) | 2024.12.04 |
| [자료구조 및 알고리즘] 고급 정렬 (0) | 2024.12.01 |
| [자료구조 및 알고리즘] 기본 정렬 (0) | 2024.12.01 |

